用 Go 制作一个脚本语言-1
无论解释器还是编译器前半部分的语言处理器都是一样的:
源代码首先进行词法分析 Lexer,由一长串字符串细分为多个更小的字符串单元。
分割后的字符串称为单词,之后处理器将执行语法分析处理器,把单词的排列转换为抽象语法树。之后,编译器会把抽象语法树转换为其他语言,而解释器将会一边分析抽象语法树一边执行运算。
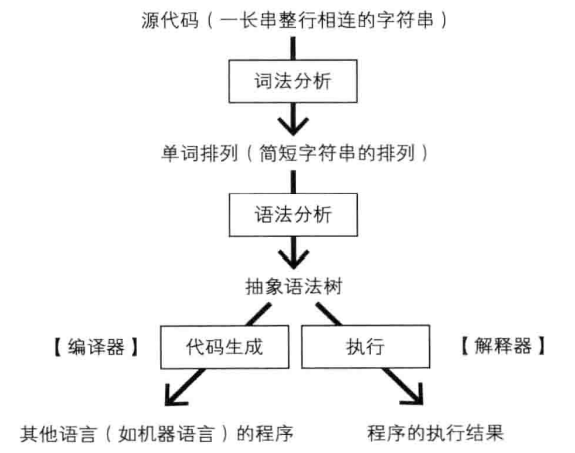
由此也能看出,编译型语言和解释型语言的区别
语言处理器的第一个组成部分是词法分析器(lexical analyzer、lexer 或 scanner)。程序的源代码最初只是一长串字符串。
从内部来看,源代码中的换行也能用专门的(不可见)换行符表示,因此整个源码实际上是一种相连的长字符串。对这种长字符串,语言处理器通常会首先将字符串中的字符以单词为单位分组,切割成多个子字符串。这就是语法分析
Token 的匹配
使用正则分割单词
使用正则表达式来匹配各种单词
下面这些正则可以在 regex101 里面测试使用
1、首先定义整型字面量,下面这个正则表示从 0 到 9 中取出一个或一个以上的数字,就能构成一个整型字面量
[0-9]+
2、然后定义标识符,下面这个正则表示至少需要一个字母、数字或下划线 _,且开头不能是数字
[A-Z_a-z][A-Z_a-z0-9]*
3、然后匹配一些特殊的符号,因为这里一段正则表示一个模式,所以这些模式需要使用 | 连接
注意这里的 \|\ 表示 ||
[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\|\||\p{Punct}
最后的 \p{Punct} 表示与任意一个符号字符匹配。
不过注意,在 Go 中无法使用这个 \p{Punct},参考 Converting the regular expression in java to golang. Correct me
需要使下面这个代替
[[:punct:]]
4、匹配字符串字面量,因为字符串里面包含了各种转义符,所以匹配起来比较复杂
"(\\"|\\\\|\\n|[^"])*"
这里匹配 \"、\\、\n
然后 [^"] 表示匹配除了 " 任意的一个字符
上面介绍了 整型字面量、标识符、特殊的符号、字符串字面量 的匹配,那如何同时匹配上面的各种模式呢?最好又能区分它们
这种时候可以使用 () 来同时匹配各模式,每一对左右括号都对应了与其包围的模式匹配的字符串。(注意,正则不要加空格,否则它也是按照一种模式匹配的)
\s*((//.*)|(pat1)|(pat2)|pat3)?
如上:
- pat1 是与整型字面量匹配的正则表达式
- pat2 与字符串字面量匹配
- pat3 则与标识符匹配。
- 起始的
\s与一个空字符串匹配,所以\s*与 0 个及 0 个以上的空字符串匹配。 - 模式
//.*则是匹配以//开始的任意长度的字符串,用于匹配注释 - 因为最后以一个
?结尾,所以仅由任意多个空白符组成的字符串也能与该模式匹配。
这里的匹配逻辑是从左到右逐个模式匹配的,左起第一个左括号对应的字符串与该括号的模式匹配,不包含含字符串头部的空白符。如果匹配的字符串是一句注释,则对应与左起第二个左括号,从第三个左括号起对应的都是 null。同理如果匹配的字符串是一个整型字面量,则对应于左起第 3 个左括号,第 2 个和第 4 个左括号都是 null
最后取得完整的正则表达式
\s*((//.*)|([0-9]+)|("(\\"|\\\\|\\n|[^"])*")|[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\|\||[[:punct:]])?
Go 正则表达式捕获子表达式
正则匹配并且可以捕获到 ( ) 这个里面的子表达式的值,参考 How to get capturing group functionality in Go regular expressions 使用 Go 去实现类似 Java 的 match.group(1) 的效果
下面的示例介绍了如何去匹配这些 Token
package main
import (
"fmt"
"regexp"
)
const regexPat = `\s*((//.*)|([0-9]+)|("(\\"|\\\\|\\n|[^"])*")|[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\|\||[[:punct:]])?`
func main() {
// 模拟一个文件
txt := []string{
`"here is a string."`,
"12345",
"// hello world",
"1 * 3 == alsritter",
}
for _, line := range txt {
regex := *regexp.MustCompile(regexPat)
pos := 0
endPos := len(line)
for pos < endPos {
if s := regex.FindString(line[pos:]); s != "" {
fmt.Println(matchToken(s, regex))
pos = pos + len(s)
}
}
}
}
func matchToken(str string, regexp regexp.Regexp) string {
res := regexp.FindAllStringSubmatch(str, -1) // -1 表示匹配全部
for i := range res {
m := res[i][1]
if m != "" { // if not a space
if comment := res[i][2]; comment != "" {
// 注释
return comment
}
if number := res[i][3]; number != "" {
// 数值
return number
}
if str := res[i][4]; str != "" {
// 字符串
return str
}
// 符号
return m
}
}
return "空白"
}
输出:
"here is a string."
12345
// hello world
1
*
3
==
alsritter
设计 Token
首先设计一个 Token 的基类
package walk
import "fmt"
const EOL = "\\n" // EOL is end of line
var eof = NewBaseToken(-1) // singleton instance
// TOF is end of file. (end of the program)
func EOF() Token {
return eof
}
type Token interface {
GetLineNumber() int64
IsIdentifier() bool
IsNumber() bool
IsString() bool
GetNumber() int32
GetString() string
GetText() string
}
// ========================BaseToken==========================
type BaseToken struct {
lineNumber int64
}
func NewBaseToken(lineNumber int64) Token {
return &BaseToken{lineNumber}
}
func (t *BaseToken) GetLineNumber() int64 { return t.lineNumber }
func (t *BaseToken) IsIdentifier() bool { return false }
func (t *BaseToken) IsNumber() bool { return false }
func (t *BaseToken) IsString() bool { return false }
func (t *BaseToken) GetNumber() int32 { panic(NewWalkError("not number token", nil)) }
func (t *BaseToken) GetString() string { return "" }
func (t *BaseToken) GetText() string { return "" }
// ==========================NumToken============================
type NumToken struct {
value int32
*BaseToken
}
func NewNumToken(line int64, value int32) *NumToken {
return &NumToken{value: value, BaseToken: &BaseToken{lineNumber: line}}
}
func (t *NumToken) IsNumber() bool { return true }
func (t *NumToken) GetText() string { return fmt.Sprintf("%d", t.value) }
func (t *NumToken) GetNumber() int32 { return t.value }
// =========================StrToken============================
type StrToken struct {
text string
*BaseToken
}
func NewStrToken(line int64, str string) *StrToken {
return &StrToken{text: str, BaseToken: &BaseToken{lineNumber: line}}
}
func (t *StrToken) IsString() bool { return true }
func (t *StrToken) GetText() string { return t.text }
// =========================IdToken============================
type IdToken struct {
text string
*BaseToken
}
func NewIdToken(line int64, id string) *IdToken {
return &IdToken{text: id, BaseToken: &BaseToken{lineNumber: line}}
}
func (t *IdToken) IsIdentifier() bool { return true }
func (t *IdToken) GetText() string { return t.text }
Lexer 词法分析程序
知道怎么匹配 Token 后,下面来看一下如何设计一个词法分析程序
不管对哪个语言,词法分析的内在工作原理都是相似的:根据语言的词法规则将输入字节流转换为 Token 流。唯一不同的是各语言的词法规则,所以通常情况下会使用一个词法生成器来构建词法分析器,Lex 是流行的词法生成器。但 Golang 选择了自己实现,其核心 scanner.go 只有 1000 行不到的代码
再来看一下这图:
词法分析阶段会逐行读取源代码提供 Token,而后续的语法分析阶段一边获取 Token 一边构造抽象语法树,它在构造中途可能会发现构造有误需要回溯若干个单词,重新构造语法树(称为回溯)。所以为了支持后续的语法分析阶段的回溯需求,需要在词法分析阶段提供接口
所以设计它有两个方法组成 Read 和 Peek
- Read:从头源码头部开始逐一获取 Token。调用 Read 时将会返回一个新的 Token
- Peek:方法则用于预读,
Peek(i)将返回 Read 方法即将返回的 Token 之后的第 i 个 Token。
如果 i 为 0 则 Peek 返回的和 Read 一样。通过 Peek,词法分析器就能事先知道在调用 Read 方法时将会取得啥 Token。如果所有 Token 都已读取,Read 和 Peek 都会返回 Token.EOF。这是一个特殊的 Token 对象
Peek 方法可以事先获知之后会取得的 Token,以避免撤销抽象树的构造,也就是说,当遇到分支路线时,不是先随意选取一条,在行不通时再返回改走另一条
这个 Peek 方法,词法分析器需要预先读取代码获取 Token,将这些 Token 暂时存在队列里面。之后 Peek 与 Read 会从里面取值并返回,其中 Read 读取后的单词会直接从队列出队。
使用 Go 简单的实现:
package walk
import (
"fmt"
"io"
"regexp"
"strconv"
"strings"
)
type ILexer interface {
Peek(i int) Token
Read() Token
}
const regexPat = `\s*((//.*)|([0-9]+)|("(\\"|\\\\|\\n|[^"])*")|[A-Z_a-z][A-Z_a-z0-9]*|==|<=|>=|&&|\|\||[[:punct:]])?`
type lexer struct {
queue []Token // list of tokens
regex *regexp.Regexp // regular expression
hasMore bool
reader *LineNumberReader // Line number reader
}
func NewLexer(reader io.Reader) ILexer {
lex := new(lexer)
lex.queue = make([]Token, 0)
lex.regex = regexp.MustCompile(regexPat)
lex.hasMore = true
lex.reader = NewLineNumberReader(reader)
return lex
}
func (l *lexer) Read() Token {
if l.fillQueue(0) {
ele := l.queue[0]
l.queue = l.queue[1:] // remove first Token.
return ele
} else {
return EOF()
}
}
func (l *lexer) Peek(i int) Token {
if l.fillQueue(0) {
return l.queue[0]
} else {
return EOF()
}
}
func (l *lexer) fillQueue(i int) bool {
for i >= len(l.queue) {
if l.hasMore {
l.readLine()
} else {
return false
}
}
return true
}
func (l *lexer) readLine() {
line := ""
if err := RecoverToError(func() {
line = l.reader.ReadLine()
}); err != nil {
PanicError(NewParseError3("read a Line error", err))
}
if line == "" {
l.hasMore = false
return
}
lineNo := l.reader.GetLineNumber()
pos := 0
endPos := len(line)
for pos < endPos {
if s := l.regex.FindString(line[pos:]); s != "" {
if err := RecoverToError(func() {
l.addToken(lineNo, s)
}); err != nil {
PanicError(NewParseError3(fmt.Sprintf("bad token at line %d", lineNo), err))
}
pos = pos + len(s)
} else {
PanicError(NewParseError3(fmt.Sprintf("bad token at line %d", lineNo), nil))
}
}
l.queue = append(l.queue, NewIdToken(lineNo, EOL))
}
func (l *lexer) addToken(lineNo int64, str string) {
res := l.regex.FindAllStringSubmatch(str, -1)
if len(res) == 0 {
return
}
matcher := res[0]
m := matcher[1]
if m != "" { // if not a space
if comment := matcher[2]; comment == "" { // if not a comment
var token Token
if number := matcher[3]; number != "" {
num, err := strconv.Atoi(number)
if err != nil {
PanicError(NewParseError3(fmt.Sprintf("error parse number word: %s", number), nil))
}
token = NewNumToken(lineNo, int32(num))
} else if str := matcher[4]; str != "" {
token = NewStrToken(lineNo, l.toStringLiteral(str))
} else {
token = NewIdToken(lineNo, m)
}
l.queue = append(l.queue, token)
}
}
}
// toStringLiteral converts a special symbol inside a string
func (l *lexer) toStringLiteral(s string) string {
sb := strings.Builder{}
len := len(s) - 1
for i := 0; i < len; i++ {
c := s[i]
if c == '\\' && i+1 < len {
c2 := s[i+1]
if c == '"' || c2 == '\\' {
i++
c = s[i]
} else if c2 == 'n' {
i++
c = '\n'
}
}
sb.WriteByte(c)
}
return sb.String()
}
编写一个简单的单元测试:
package walk
import (
"reflect"
"strings"
"testing"
)
var txt = "while i < 10 { \n" + // note: "//n" is a Token
" sum = sum + i \n" +
" i = i + 1 \n" +
"}\n" +
"sum"
func Test_lexer_Read(t *testing.T) {
lexer := NewLexer(strings.NewReader(txt))
tests := []struct {
name string
want Token
}{
{
name: "id Token 01",
want: NewIdToken(1, "while"),
},
{
name: "id Token 02",
want: NewIdToken(1, "i"),
},
{
name: "id Token 03",
want: NewIdToken(1, "<"),
},
{
name: "number Token 01",
want: NewNumToken(1, 10),
},
{
name: "id Token 04",
want: NewIdToken(1, "{"),
},
{
name: "id Token 05",
want: NewIdToken(1, "\\n"),
},
{
name: "id Token 06",
want: NewIdToken(2, "sum"),
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := lexer.Read(); !reflect.DeepEqual(got, tt.want) {
t.Errorf("lexer.Read() = %v, want %v", got, tt.want)
}
})
}
}